VLAモデル(ロボットVLA)とは?仕組み・VLMとの違い・ロボット制御の進化をわかりやすく解説
VLAモデルが登場する以前のロボットは、動作を事前に細かく決める必要がありました。もし、ロボットが人の言葉を理解し、自ら「見て・考えて・動く」ことができれば、多くの業務はより効率的になるはずです。 これらを実現するアプロ […]
www.icom-giken.com

近年、AI技術の進化によりロボットの能力は大きく変化しつつあります。特に注目されているのが視覚言語モデル VLM(Vision-Language Model) や VLA(Vision-Language-Action)モデル と呼ばれる新しいAI技術です。
従来の産業用ロボットは、決められた位置にある物に対して、決められた動作を正確に繰り返すことを得意としてきました。そのため、大量生産ラインのように条件が固定された工程では非常に高い性能を発揮します。
一方で、近年の製造業や物流業では
などにより、ロボットにも より高度な判断能力や環境理解能力 が求められるようになっています。
目次[]
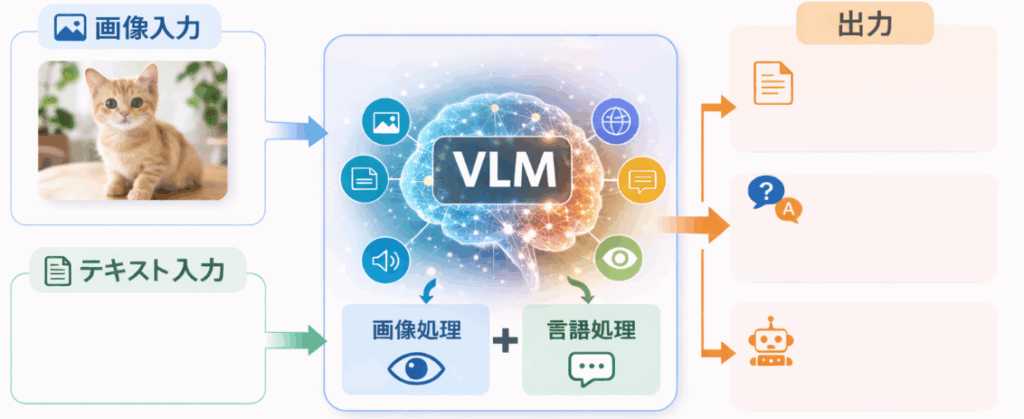
VLMとは(Vision-Language Model)の略で、視覚情報と言語情報の相互関係を取り扱うAIモデルのことです。
| AIの種類 | 主な機能 |
|---|---|
| 画像認識AI | 画像を識別 |
| 自然言語AI | 文章を理解 |
従来のAIは上記のように、それぞれ別の技術として発展してきました。しかしVLMでは、画像情報と文章情報を同時に理解することができます。
近年AIの分野では LLM(Large Language Model) が広く知られるようになりました。ChatGPTなどの生成AIも、このLLMをベースとした技術です。
しかしロボットAIの分野では、言語だけでなく 視覚情報も扱う必要があります。
そこで登場したのが VLM(Vision-Language Model) です。
まずは LLMとVLMの違いを整理してみましょう。
| 項目 | LLM(Large Language Model) | VLM(Vision-Language Model) |
|---|---|---|
| 技術の概要 | 大量の文章データを学習し、文章の理解や生成を行うAIモデル。自然言語処理を目的として開発された。 | 画像と文章を同時に理解できるAIモデル。視覚情報と自然言語を結びつけて理解する。 |
| 主な入力 | テキスト(文章) | 画像+テキスト |
| 出力 | テキスト(回答・文章生成) | 画像内容の説明、質問回答、物体認識など |
| AIの役割 | 知識回答、文章生成、会話AIなど、主に言語処理を担当する。 | 画像の意味理解や状況説明など、視覚と意味の結び付けを行う。 |
| できることの例 | 「日本の首都は?」と質問すると「東京」と回答する。 | 「この画像の中で赤い箱はどれ?」と質問すると対象を特定できる。 |
| 主な用途 | チャットボット、文章生成、プログラム生成、翻訳など | 画像理解、マルチモーダルAI、ロボット認識、視覚QA |
| 代表的モデル | GPT、Claude、Llama | GPT-4V、Gemini、CLIP |
VLMは、画像と文章を同時に理解できるAIモデルです。
これにより、従来のAIでは難しかった「画像と意味の結びつけ」が可能になります。
例えば、次のような処理を行うことができます。
| 入力 | VLMの処理 |
|---|---|
| 画像 | 画像の内容を説明 |
| 画像+質問 | 画像に関する質問に回答 |
| 画像 | 物体を認識 |
| 画像+指示 | 対象物を特定 |
例えば「この画像に何がありますか?」という質問をすると「机の上に赤い箱があります」といった回答を生成できます。
また、「この画像の中で赤い箱はどれですか?」と質問すると、対象となる物体を特定することも可能です。
つまりVLMは画像を単なるピクセル情報ではなく“意味”として理解するAIと言えます。

ロボットが現実世界で作業を行うためには、単に動作を繰り返すだけではなく、周囲の状況を理解する能力が必要になります。
例えば、次のような指示を考えてみましょう。
「机の上にある赤い箱を取ってください」
人間にとっては簡単な指示ですが、この作業には次のような処理が含まれています。
という複数の処理が必要になります。
従来のロボットシステムでは、これらの処理を
などの複数のシステムで実装する必要がありました。しかしVLMを利用すると、画像と意味を統合的に理解することができるため、より柔軟なロボット制御が可能になると期待されています。
ここで登場するのが VLA(Vision-Language-Action)モデルです。
VLAとは、Vision-Language-Actionの略で
| 要素 | 内容 |
|---|---|
| Vision | 視覚情報 |
| Language | 言語理解 |
| Action | 行動生成 |
を統合したAIモデルです。
VLMとVLAはよく混同されますが、役割は異なります。
| 技術 | 役割 |
|---|---|
| LLM | 言語理解 |
| VLM | 視覚+言語理解 |
| VLA | 視覚+言語+行動 |
つまりLLM → VLM → VLAという形でAIは進化しています。簡単に言えば
と言うことができます。
従来ロボットとの違い
従来のロボットシステムは、次のような多段階構造で構成されています。
センサー
↓
画像認識
↓
判断ロジック
↓
タスク計画
↓
ロボット制御
この構造では
- システム構成が複雑になる
- 調整工数が多い
- 環境変化に弱い
という課題があります。一方、VLAモデルでは
画像 + 指示
↓
AIモデル
↓
ロボット動作という形でエンドツーエンド制御が可能になります。
これにより柔軟性の向上やシステム簡素化、自律判断などが期待されています。

現在、世界中でロボットAIの研究が進んでいます。代表的なVLA関連モデルには次のようなものがあります。
| モデル | 開発 |
|---|---|
| RT-2 | Google DeepMind |
| Gemini Robotics | |
| GR00T | NVIDIA |
| π0 | Physical Intelligence |
VLM(Vision Language Model)やVLA(Vision Language Action)技術は、製造業のロボット活用を大きく変える可能性を持つ技術として注目されています。
従来の産業用ロボットは、高精度で同じ作業を繰り返すことには非常に優れていますが、環境の変化や対象物の違いには弱いという特徴がありました。
一方でVLM / VLA技術を活用することで、ロボットが環境を理解し、柔軟に作業を判断することが期待されています。
ここでは、製造業や物流分野で期待されている具体的な活用例について解説します。

まず注目されているのが、多品種生産への対応です。従来の産業用ロボットは、ワークの位置や種類が固定されていることを前提に設計されることが多く、製品が変わるたびにティーチングやプログラムの変更が必要でした。
一方、VLMを活用したロボットは、カメラ画像から対象物の形状や種類を認識し、その意味を理解することができます。これにより、異なる形状やサイズのワークにも柔軟に対応できる可能性があり、多品種生産ラインにおける自動化の幅を広げる技術として期待されています。

次に期待されているのが、ティーチング作業の削減です。現在のロボット導入では、ティーチングやプログラム作成、動作調整などに多くの時間と専門知識が必要になります。
VLAモデルでは、視覚情報と言語理解、そしてロボット動作の生成を統合することで、「この箱を棚に置いて」といった自然言語の指示から作業を実行できる可能性があります。これが実用化されれば、従来必要だった細かなプログラム設定を減らし、現場作業者でもロボットを扱いやすくなると考えられています。

さらに、物流や工場内搬送といった分野でも活用が期待されています。物流現場では、ピッキングや仕分け、混載パレタイジングなど、状況に応じた判断が求められる作業が多く存在します。
これらの作業では、箱のサイズや形状、配置が毎回異なるため、従来のロボットでは対応が難しい場合があります。VLMやVLAを活用することで、対象物を認識し状況を理解したうえで作業を判断できるようになれば、より柔軟な物流自動化が実現する可能性があります。
VLMとは、画像(Vision)と文章(Language)を同時に理解できるAIモデルのことです。
従来の画像認識AIは「物体を識別する」ことが主な役割でしたが、VLMは画像の内容を言語として理解し、説明することができます。
例えば、画像を見て
「箱がパレットの上に積まれている」
「人が部品を持っている」
といった状況を理解することができます。
このような能力を活用することで、ロボットが環境を理解しながら作業する技術の研究が進められています。
VLMとVLAの違いは、AIが「行動できるかどうか」です。
| 技術 | 機能 |
|---|---|
| LLM | 言語を理解する |
| VLM | 画像と言語を理解する |
| VLA | 画像・言語を理解してロボットを動かす |
VLMは主に「理解するAI」であり、
VLAはその理解をもとに「行動するAI」です。
つまり、VLMはロボットの認識技術として、VLAはロボット制御技術として活用されると考えられています。
現在の製造業では、VLMそのものを直接使ったロボットシステムはまだ研究段階のものが多いとされています。
ただし、画像認識AIを利用した
などの技術はすでに実用化されています。
今後、VLMやVLAの研究が進むことで、より柔軟なロボット自動化が実現すると期待されています。
完全に不要になるとは限りませんが、ティーチング作業が大幅に減る可能性があります。
従来のロボットでは
などが必要です。
VLMやVLAが実用化されると、AIが環境を理解して動作を生成するため、作業設定が簡単になる可能性があります。
VLMやVLAの実用化には、いくつかの課題があります。
主な課題は次の通りです。
| 課題 | 内容 |
|---|---|
| データ不足 | ロボット学習データが不足 |
| 安全性 | AI誤判断による事故リスク |
| ハードウェア | ハンド・センサー性能 |
| 計算能力 | GPUなどの計算リソース |
特にロボットAIでは、実世界のデータ収集が難しいため、現在も多くの研究が進められています。

「自社の荷物で本当に自動化できるのか?」
そんな不安をお持ちの方も、iCOM技研なら安心です。
箱のサイズ・重量・品種情報をお送りいただければ、実機を用いたシミュレーションが可能です。
iCOM技研では、ユニバーサルロボットをはじめとする各種ロボットメーカー製品を取り扱い、用途や作業環境に応じた最適なシステムをご提案します。
まずはお気軽にお問い合わせください。
お客様の現場に即した自動化の第一歩をお手伝いします。
協働ロボット導入をお考えなら、まずはこちら。
初心者の方でも基礎からわかる3つの資料が手に入ります。