TikTokを運営するByteDanceが開発した動画生成によるロボット行動生成AI「GR-1」について、システム構成や期待される効果を紹介していきたいと思います。

目次[]
概要
ロボット技術の進化により、産業や日常生活においてロボットの役割がますます重要になっています。特に、ロボットが人間のように行動するためには、効率的で自然な動作生成が求められます。本ブログでは、ByteDanceがTikTokで培った動画生成技術を活用し、ロボ行動生成AI「GR-1」について紹介します。このAIは2億パラメータを持ち、Transformerモデルをベースにしています。
システム構成
ロボット行動生成AIのシステムは以下のように構成されています。
データ収集
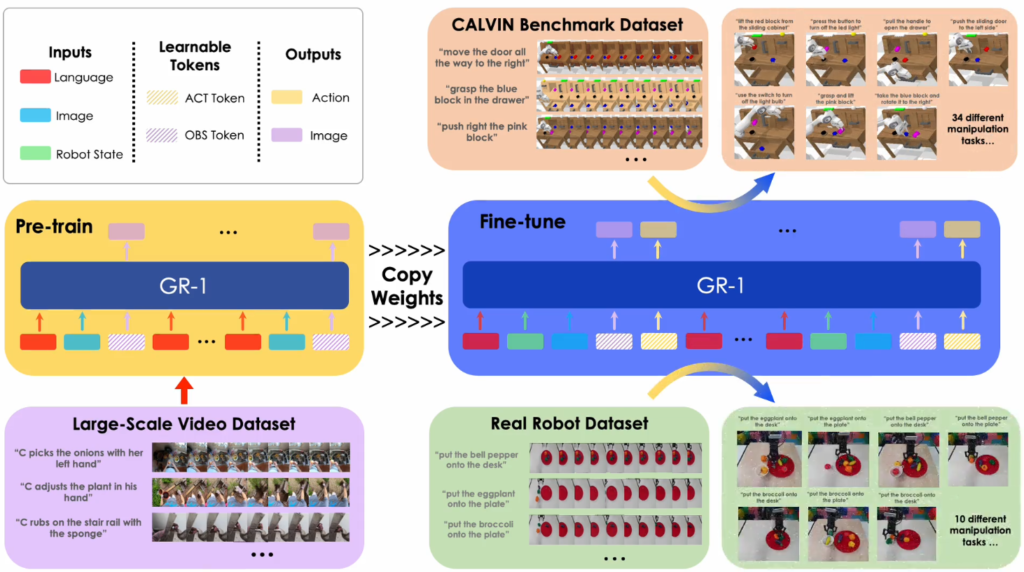
GR-1での学習は、2段階のフェーズで行う。1つは動画生成能力を獲得させる事前学習、もう1つはその事前学習モデルを基にしたロボット遠隔操作データでのファインチューニングである。GR-1では、約半年分に相当する動画データを事前学習に用いており、公開の動画データセット「Ego4D」(人間の日常生活における様々な作業や動作の一人称で撮影した動画)を使用しています。事前学習時はモデルにはロボット行動の出力は行わず、動画生成に専念します。ファインチューニング時には、入力側にタスク指示のテキストおよびロボットの状態量(手先姿勢など)、出力側にロボット行動をそれぞれ追加し、ロボット遠隔操作データで教師あり学習させます。
データ前処理
収集した動画データを解析し、動作の特徴を抽出します。特に、関節の動きやフレームごとの動作パターンなどを詳細に分析します。「Ego4D」から得られる動画データが限定的なタスクのロボットの学習に有用なものが少ない場合でも、従来の限定的なタスク関連のデータのみを事前学習する場合と比較すると、大規模なデータを事前学習することができ、ロボットの少ない経験を補うことができます。
動作モデル生成
抽出された特徴をもとに、Transformerモデルを用いて動作モデルを生成します。このモデルは2億パラメータを持ち、高度な動作生成を可能にします。他のTransformerをベースにした大規模言語モデル(LLM)と比較すると、かなり小規模なパラメータ数ですが、GR-1はテキスト生成という側面をカットした動画生成に寄っていることから、この規模でも十分だと考えられます。
テスト
シミュレーションと最適化
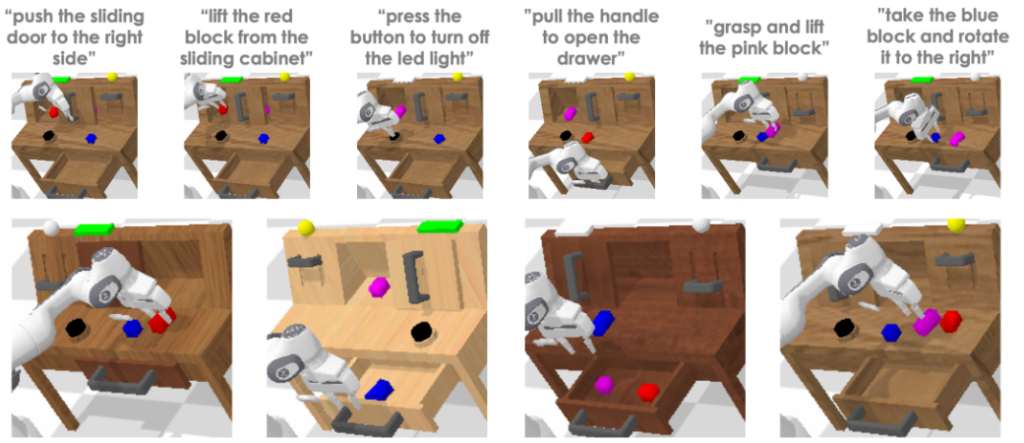
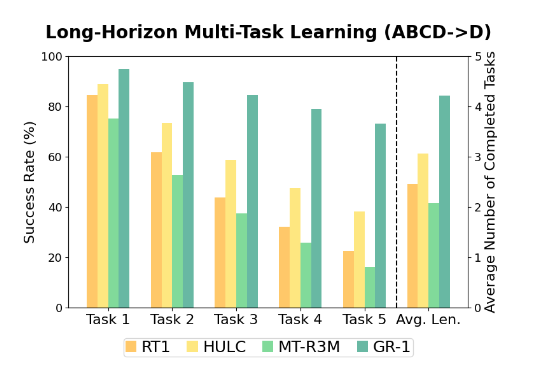
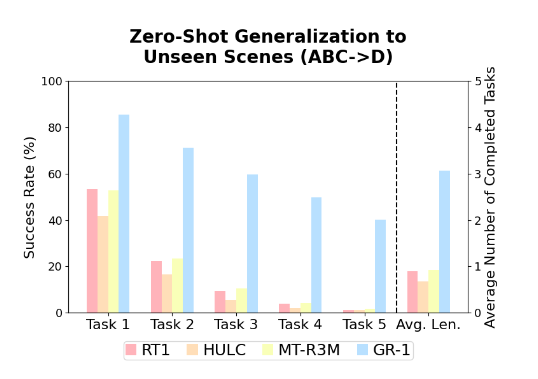
生成された動作モデルをシミュレータ上で実行し、動作の精度や効率を評価・最適化します。これにより、実際のロボット上での動作がスムーズになります。ByteDanceはシミュレータ上でベンチマークも実施しました。テキストによるタスク指示を基に、シミュレータ上で複数の異なるタスクを連続して実施するlong-horizon(長期視点)のマニピュレーションのベンチマーク「CALVIN」を用いました。GoogleのRT-1を含めて他手法と比較した結果、GR-1は他手法を大幅に上回る成功率を示しました。
実装と検証
最適化されたモデルをGR-1ロボットに実装し、現場での動作を検証します。このステップでは、実環境での調整や微調整が行われます。
GR-1 が現実世界でどのように機能するかを評価するために、ピッキングロボット実験を広範囲に実行します。まず、3 つの設定で物体の輸送を評価します。Seen Object, Unseen Instances (unseen object instances of seen categories), Unseen Categories (unseen objects of unseen categories)です。指示の例には、「ブロッコリーを皿の上に置く」などがあります。このタスクは、ロボットがシーン内で正しい物体を接地し、それをつかんで正しい領域に配置する必要があるため、困難です。また、接触の多い多関節物体の操作に関する実験も行います。指示の例には、「引き出しを開ける」などがあります.

障害物ありのSeen Object
Unseen Instances
Unseen Categories
多関節オブジェクトの操作
ロボ行動生成で期待される効果
動画生成を用いたロボ行動生成AIで期待される効果は以下の通りです。
テキスト指示によるタスク実行
ロボットの行動を動画生成することで、世界モデル(世の中のものの動きを把握・予測する能力)を把握することができ、ロボット自身がロボットの具体的な動きをプランニングできるようになります。つまり、テキストベースでタスク支持を行うことで、ロボットの行動を生成することができます。
現在のロボットに必要かつ負担が大きいティーチングや面倒なプログラミングを将来的には、ChatGPTのようにテキストを入力するだけでロボットを動かすことが可能になるかもしれません。
少ない学習で高い効果を得られる
ロボットの学習データを動画生成で補うことで、学習に必要なモデルを少量で済ますことができます。つまり、果物をピッキングするロボットの動作を行いたい場合に、ロボ行動生成を用いて動画生成する。そうすることで、ピッキングに必要な学習データ(果物の種類などやロボットの動き)を補うことができるのです。また、新しい動作やタスクに迅速に対応することができ、変化しやすい環境での活用やニーズに適応することができ、対応に必要な時間・コストを削減することができます。
まとめ
動画生成によるロボ行動生成AIは、効率的で自然なロボット動作を実現するための強力なツールです。ByteDanceの先進的な技術とTikTokから収集されたデータを活用することで、GR-1は高度な動作を可能にしています。動画生成技術を活用することで、従来の方法では達成できなかった高度な動作生成が実現され、少量のロボデータで高い成功率を維持できることが示されました。今後もこの技術の進化により、さらに多様なロボットの活躍が見込まれます。
参考文献
https://gr1-manipulation.github.io/
iCOM技研の取り組み
今回は動画生成によるロボット行動生成についての紹介をしました。
iCOM技研はSIer事業を行っており、協働ロボットシステムの導入を行っています。弊社は、協働ロボットの販売からソフトウェア開発、ロボットスクールまで行っています。
また、関連するブログも随時更新していく予定です。
展示会事例 協働ロボット×AI
iCOM技研による自動化のご提案|まずはシミュレーションから

「自社の荷物で本当に自動化できるのか?」
そんな不安をお持ちの方も、iCOM技研なら安心です。
箱のサイズ・重量・品種情報をお送りいただければ、実機を用いたシミュレーションが可能です。
- 実データに基づいた検証で、導入効果を事前に確認
- 単なる装置提案ではなく、現場に即した自動化プランをご提案
- 協働ロボットの操作指導・立ち上げ支援までワンストップで対応
iCOM技研では、ユニバーサルロボットをはじめとする各種ロボットメーカー製品を取り扱っています。そのため、用途や作業環境に応じた最適なシステムをご提案します。
まずはお気軽にお問い合わせください。
お客様の現場に即した自動化の第一歩をお手伝いします。