米Google(グーグル)は、最先端のマルチモーダル大規模言語モデル(LLM)「Gemini 2.0 Flash」を発表しました。
この取り組みは一般には公開されておりません。ヒューマノイドロボットを開発する米Apptronik社のような一部のパートナー企業に限定的に配布されました。
今回は、日経ロボティクス「グーグルがついにGeminiをロボットAI向けに投入」について解説します。
目次[]
なぜ今、ロボットAIに大規模言語モデルが求められるのか

いきなりロボット遠隔操作データでfine-tuningするのではなく、まずは通常のGeminiの空間把握能力を増強した。このバージョンは「Gemini Robotics-ER(Embodied Reasoning)」と呼ぶ。この段階ではロボット行動を直接生成する能力はなく、通常のVLMのままである。 左はグリッパでの把持点を2次元画像上で推定した結果、右は3次元bounding boxを推定した結果。(写真:グーグルのYouTube動画より)
近年、製造・物流業界では、単純作業の自動化だけでなく、人手でしか対応できなかった“柔軟で複雑な作業”の自動化が求められています。
AIとロボット組み合わせることで、急速に人が行っている作業をロボットが代替すると考えられています。AIの導入によりエラーの削減や作業速度の向上が期待できます。代替が進めば、人はよりクリエイティブな作業に注力できるようになります。
専門用語なしで10秒で分かるAI×ロボット
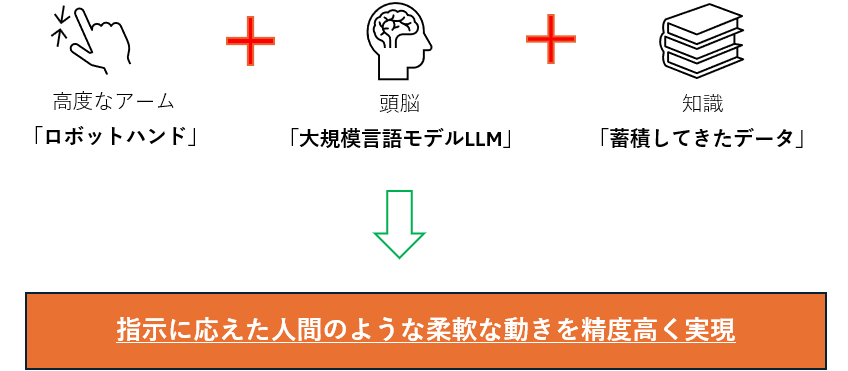
高精度なアーム(身体)と大規模言語モデル(頭脳)、そして長期間かけて蓄積されたデータを組み合わせることで、人間のような柔軟な作業をこなせるようになってきました。
たとえば、「洗濯物をたたんで」とロボットに話しかけるとします。それを本当に実行できる未来は現実になりつつあります。実際にグーグルは、最新の言語モデル「Gemini 2.0 Flash」をベースに、ロボット向けに特化した「Gemini Robotics」を開発しました。また、双腕ロボットによる作業の成功率を大幅に高めています。
この進化の裏には、1年をかけて数千時間もの遠隔操作データを集め、それをAIに学習させるという、地道な取り組みがありました。つまり、ロボットが高い精度で働けるようになったのは、データをためて、それを使って動かすことで精度が向上したからに他なりません。
だからこそ、今まさに大規模言語モデルがロボットAIに求められており、人とロボットが共に働く社会への重要な一歩となっているのです。
グーグルがGemini Roboticsで示す“新しいロボットAI像”
今回の発表に、アーキテクチャや理論的な面での目新しさはあまりない。技術的な新規性の追求というよりも、Geminiを使うとどこまでのことが可能なのかを確かめるために作られたのがGemini Roboticsだといえる。
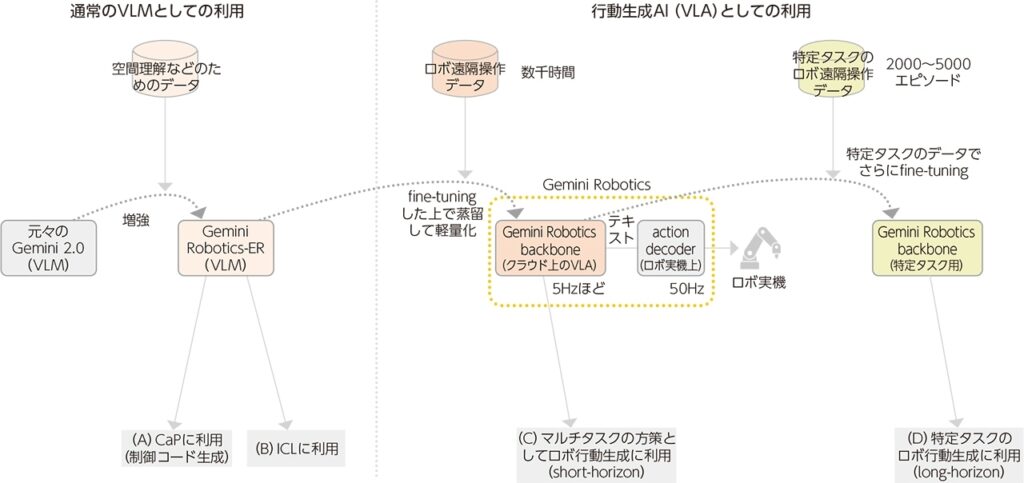
Gemini Roboticsは、チャットAIなどに使われる大規模モデル「Gemini 2.0 Flash」を、ロボット操作の実データで学習し直して構築されています。テキストと視覚情報を理解し、具体的な行動を出力する「VLA(Vision-Language-Action)モデル」という設計思想に基づいており、従来のルールベース制御では難しかった柔軟な意思決定と動作の一体化を実現しています。
データの蓄積により精度を向上
このモデルの開発では、グーグルがオープンソースで発表した双腕ロボット「ALOHA 2」を用いて、1年かけて数千時間分の遠隔操作データを蓄積しました。
さらに、膨大なパラメータを持つGeminiを“蒸留”という手法で軽量化。ロボット制御に必要な5Hz程度のリアルタイム応答を実現しています。
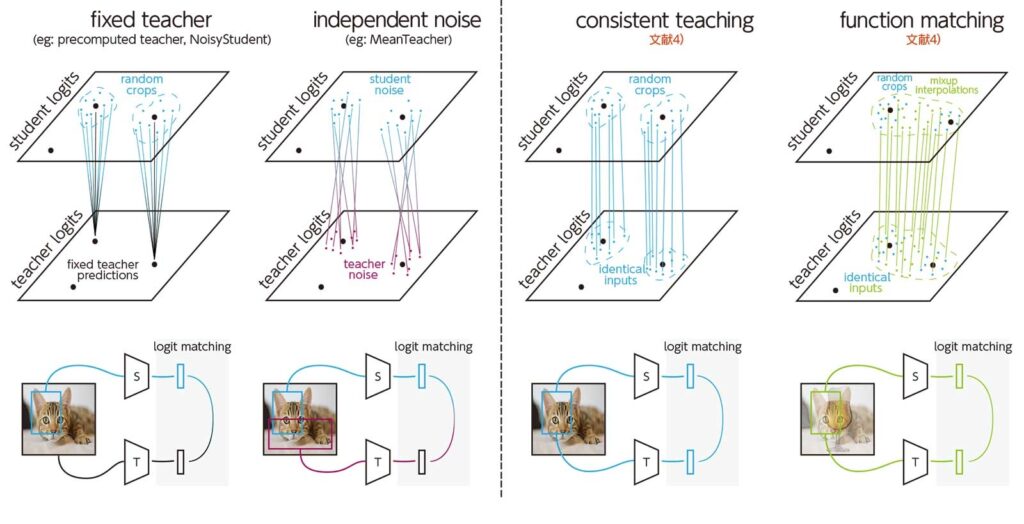
左端は、教師NNが固定の入力画像を受け取り、生徒NNがランダムなオーグメンテーションを受ける場合。左から2番目は、教師と生徒がそれぞれ個別のオーグメンテーションを受ける場合、左から3番目は教師と生徒が同一のオーグメンテーションを受ける場合、右端は教師と生徒が同一のオーグメンテーションを受けた上でmixupを施した場合。(図:文献4のL. Beyer et al.,“Knowledge distillation: A good teacher is patient and consistent,”より)
構成としては、クラウド上で実行される「backbone(AIの頭脳)」と、ロボット本体側で動作する「action decoder(実行指令の翻訳役)」を分離。両者がカメラ画像や関節角のデータを共有しながら、数ステップ先の動作をまとめて出力する「action chunking」により、ロボットに滑らかで連続的な動作を実現させます。
ベンチマークで見えた“実力”
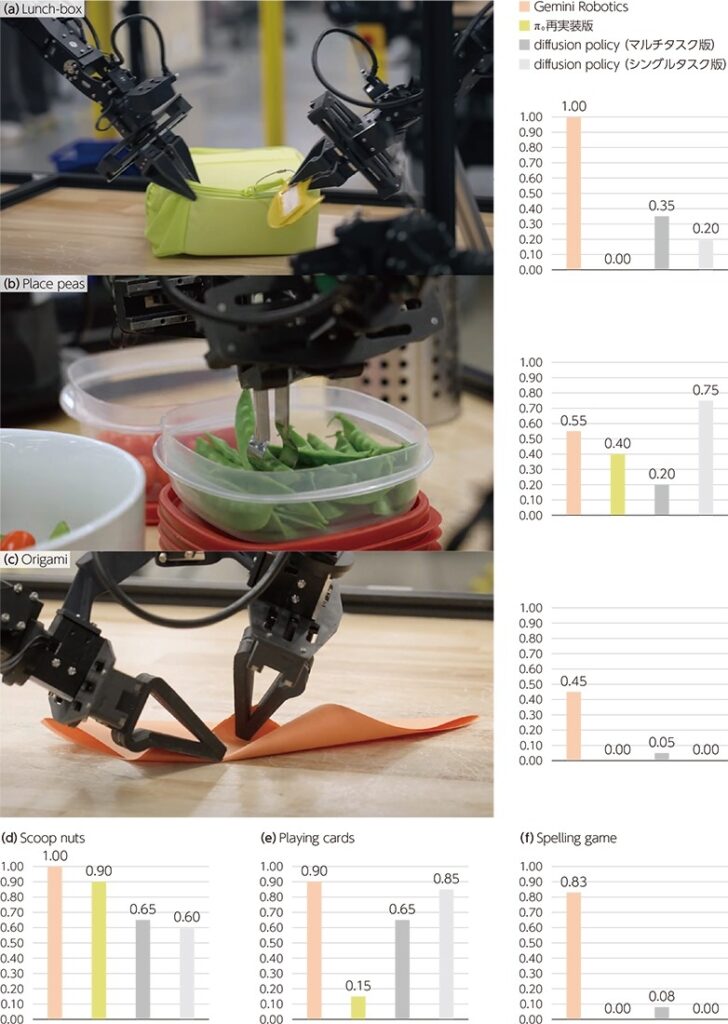
Gemini Roboticsを各タスクのデータでfine-tuningした図4(D)の設定での実験結果で、縦軸は成功率を示す。(a)入れ物に食べ物を入れてチャックを閉める(Lunch-box)、(b)絹さやをトングで把持して皿に盛る(Place peas)、(c)折り紙でキツネを折る(Origami)、(d)ナッツをスプーンですくって皿に入れる(Scoop nuts)、(e)カードを3枚取り、1枚だけ捨てる(Playing cards)、(f)文字のブロックを拾って単語にする(Spelling game)、である。写真は各タスクのイメージ。(写真:グーグルのYouTube動画より)
複数のタスクで従来技術を圧倒
グーグルは、Gemini Roboticsを用いて20種類の実作業タスク(物の受け渡し、折り紙、弁当袋の詰め作業など)で、他社の最新モデルと比較。競合モデルである「π0 re-implement」や「Diffusion Policy」よりも、大半のタスクで成功率が2倍以上高い結果を示しました。
特に注目すべきは、「服をたたむ」「ナッツをすくう」といった器用さが求められる作業でも高い成功率を記録している点です。これは、従来のAIには難しかった“連続的かつ細やかな動作”の領域で、大きな前進があったことを意味します。
他のロボット機種にも展開可能

ALOHA 2以外のロボット機体でも、少数の追加学習データを使って高い成功率を達成しました。これは今後の。協働型ロボットへの応用の可能性を広げる成果といえます。協働ロボット以外のロボットも例外ではありません。
今後、教示作業などが必要なくなり、さらに実用性が向上する事が見込まれます。逆を言えば、ロボット×AIは、今後の産業の成長の大きなカギと言えます。
まとめ
最先端でもなお残る課題
一方で、現時点ではまだ完全自動化に至るには課題も残されています。特に、「long-horizon task(複数の動作を連ねる複雑作業)」では、タスクごとに数十〜100時間単位の追加学習が必要であり、現実の導入にはコスト面・データ面の壁があります。
協働型AIロボットへの期待
こうした背景から、今後はAIがすべてを自律判断するのではなく、人との協働を前提とした“協働型AIロボット”が主流になると見られます。さらに、現場環境や業務内容に応じて、柔軟に動かせるロボット+高性能AIという組み合わせこそが、現実的な自動化の鍵を握っているのです。iCOM技研も、こうしたAIによる協働ロボットの実用性向上に積極的に取り組みます。また、協働ロボットに関する質問やお問い合わせはページ下部でお待ちしております。